![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
Previously: The basics of one sample
and what you need to know about testing the difference between a (single) sample mean and some
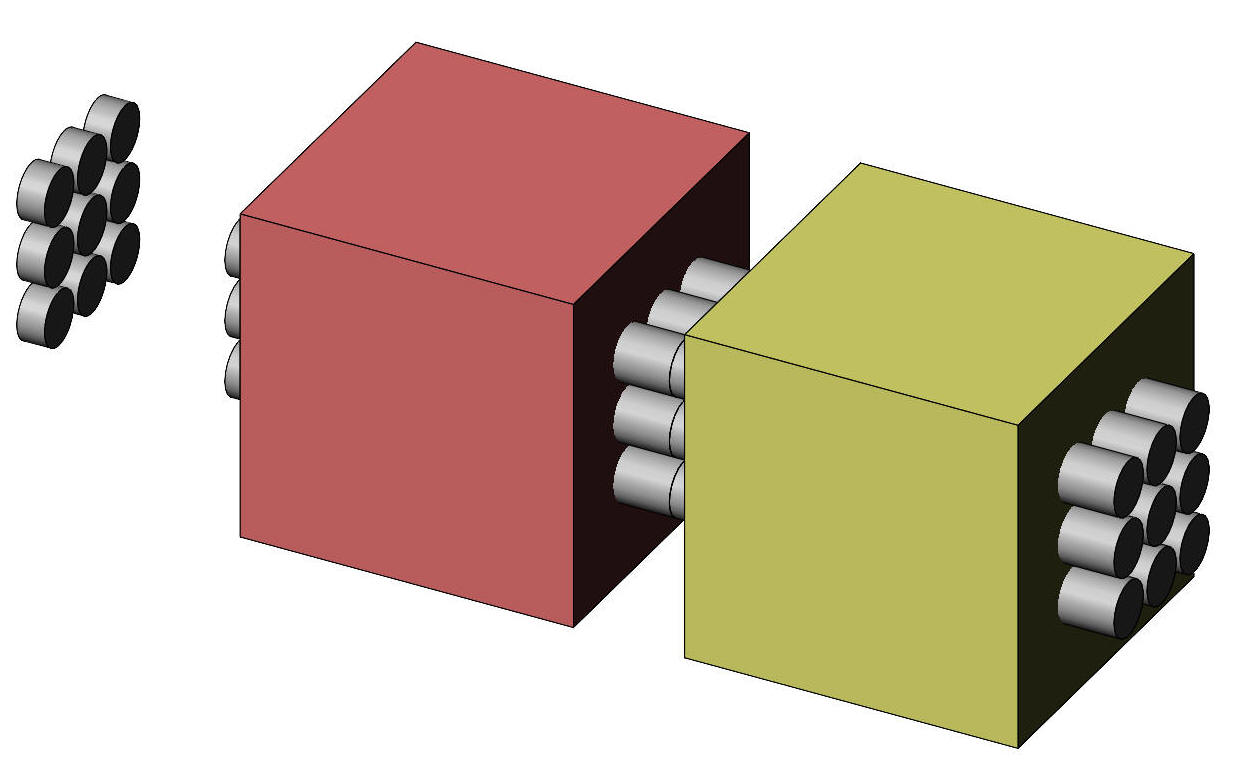
specific value. This page is concerned with testing the difference between two sample means, where each sample comprises the same group of subjects, and its connection with correlation and regression. A group of 9 subjects undertake an experimental treatment after which they are scored on a memory test. The same subjects return a day later, take tea and biscuits, and are then scored again on the memory test. This data comprises the control data. The data is illustrated in Figure 1 and shown in Table 1, where each subject is called a case. Projecting cylinders signify the same subjects in both treatment conditions, and the array on the left signifies the subject average scores across their treatments. The design is called "dependent samples" in the context of a two-sample design, and "repeated measures" in the context of the analysis of variance.
Figure 1. Representation of a dependent samples design. We used the same numbers in the discussion of two independent samples; the data has been rearranged to represent two dependent samples while retaining the same means and standard deviations. Using the same numbers will allow a comparison with the results from when the data was treated as independent. Table 1. Memory scores for experimental and control data.
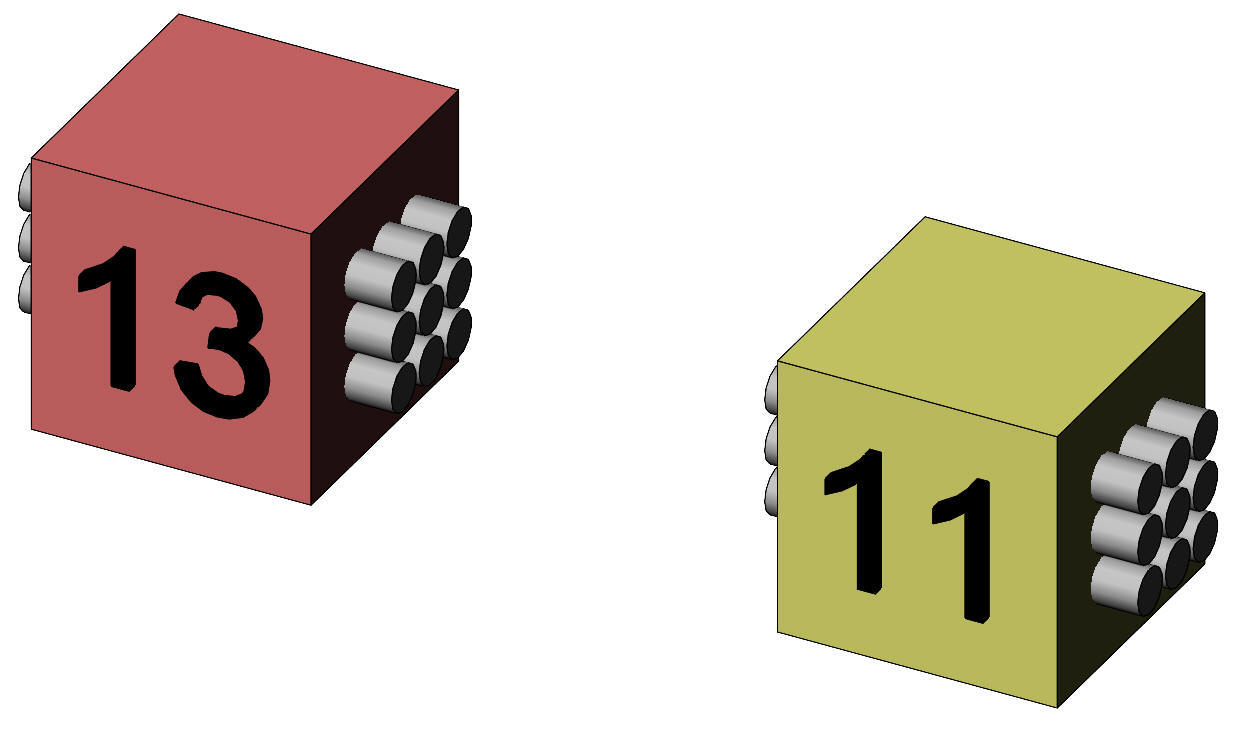
Note that the list of cases comprises 9 entries because each case (subject) has two scores. The two samples of data, experimental and control, are dependent. The data can also be called "matched", "paired", or "with repeated measures". The data is represented in Figure 2. The experimental group mean is shown as a red cube and the control group mean is shown as a yellow cube.
Figure 2. Representation of the sample means of dependent samples. This experiment as presented may seem to be "gold standard". Although it comprises an experimental group and corresponding control data, however, it is not immediately obvious that the control data is unbiased; for example, the subjects might have remembered some of the memory test items from the previous day, or it would be better to have the subjects take their control test the day before the experimental treatment rather than afterwards. The problem of bias is common when subjects serve as their own controls. We will nevertheless proceed with our data analysis on the assumption that there are no biases, and explore whether having subjects serve as their own controls gives a more powerful experimental design. The reason for constructing a design where the data is paired or matched is the assumption that the variation between cases can be reduced or mitigated because of an expected similarity or consistency of response of a case to a different treatment. For our data, we may expect that different subjects will have rather different memory scores, but we also expect that a particular subject will have a similar score over a period of time (§1). If we observe a change in their particular score following a treatment we have better evidence that the treatment had an effect. §1 The consistency of one score with another may be measured by the correlation, r, between them.
Testing the difference between two dependent sample meansWe wish to compare the mean experimental score with the mean control score. Table 2 shows the descriptive statistics of mean, standard deviation, sample size, and standard error of the sample mean. While the total number of data points N is 18, the data is paired. The sample sizes are n = 9 for the experimental data and n = 9 for the control data. Table 2. Descriptive statistics for experimental and control data.
It looks like the experimental mean score is 2.0 higher than the control, but is this "real" or could it be a chance difference? As before, we seek the probability of observing such a mean difference by chance by comparing it with its standard error. In a two dependent samples experimental design there are three approaches to determining the standard error of the difference between two dependent means — using the correlation coefficient, using the change score, and using the between-subjects variance. Note that in these and other calculations on this page there may be rounding errors; the values reported here have been rounded to 2 decimal places, and calculations made with the rounded values may show minor disagreement in the second decimal place.
Dependent samples correlation analysisBecause the data is paired, we may correlate the experimental scores with the control scores for our subjects. Table 3 shows the results. Table 3. Correlation between
experimental and control data.
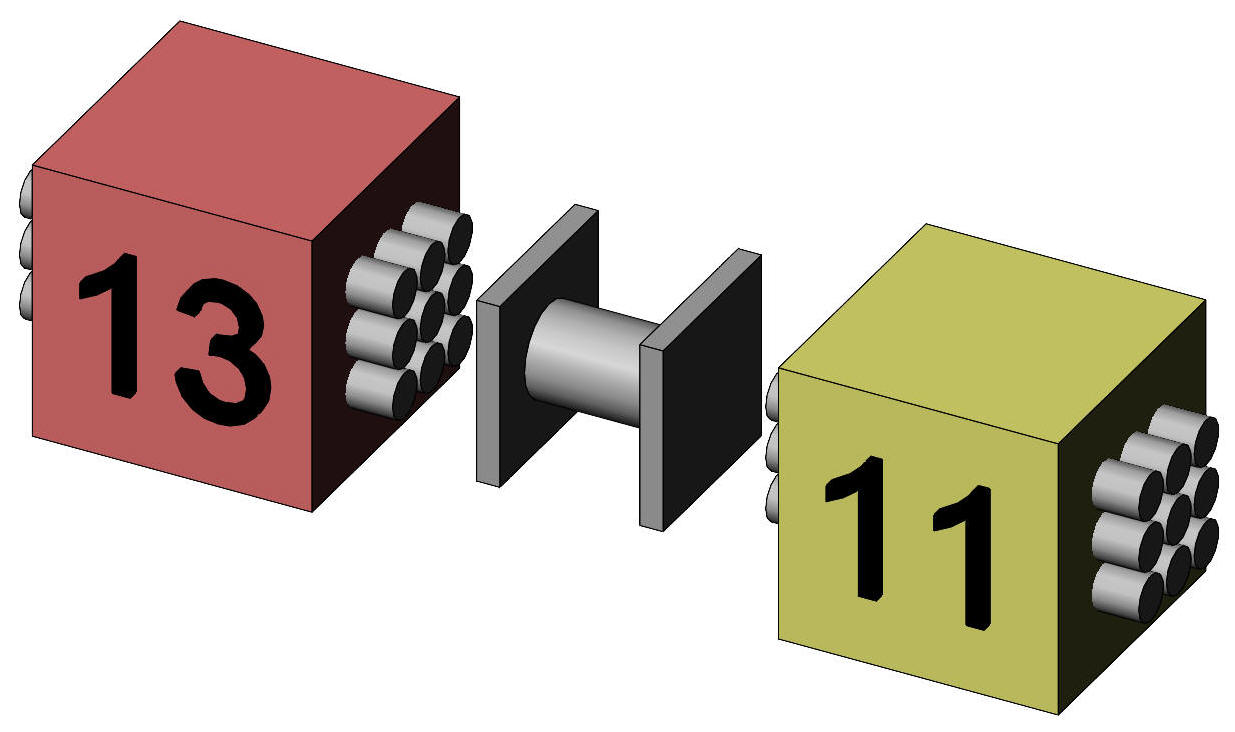
This significant correlation tells us that subjects with higher control (baseline) scores tend to have higher experimental scores and, vice versa, that subjects with lower control (baseline) scores tend to have lower experimental scores. Given the presumed context of the experiment, this is unsurprising since it suggests that the subjects' memory scores are consistent between the experimental and control conditions. We should remember that the correlation tells us nothing about the average levels of memory in the two conditions; this is given by the difference the condition means. Instead, the correlation suggest that, whatever the difference between experiment and control might be, a given subject's memory score remains relatively low or relatively high regardless. Where two samples are dependent, such as our experimental and control data for the same subjects, the variance of the difference between two items of data is equal to the sum of the variance of each minus a correction due to the correlation between the data. The correction is 2 · r · sE · sC, where sE is the standard deviation of the experimental group data and sC is the standard deviation of the control group data. We saw this before for independent samples, though the correction term was not mentioned because r = 0 for such samples. In the case of our data, the SE of the difference between the two dependent means is given by √ (0.412 + 0.412 − 2 · 0.75 · 0.41 · 0.41) = 0.29. Notice that the effect of the correlation, if positive, is to reduce SEdiff, that is, to reduce the variation expected in the difference between the sample means. Note that the calculation assumes that the population variances are equal. If there is any doubt about the tenability of this assumption, there are tests to check for equality, and to suggest adjustment to the degrees of freedom if there is significant inequality, a topic picked up in a future page. As before, note that referring the test statistics to the t distribution assumes that the mean difference is distributed as t. If N is large, we could refer the test statistic to the normal distribution, assuming that the mean difference is normally distributed. The Central Limit Theorem (CLT) tells us that this is the case for increasing N no matter the shape or distribution of the data items themselves. A value of N > 30 is taken by convention to be large enough for the CLT to apply to the sampling behaviour of a mean difference. Introducing the correction to the standard error based on the correlation coefficient does not change the application of the CLT, but there is less agreement as to when it might apply. Some authors suggest N > 100. In the case of dependent samples, the degrees of freedom for SEdiff is given by n − 1, where n is the number of pairs or, equivalently, the number of cases. In the case of our data, the df for SEdiff is 8. We can now construct our test statistic, dividing the difference between the means by the SEdiff. This test statistics is a t score, and in the case of our data t = 2 / 0.29 = 6.93 with df = 8. The probability of this value of t is 0.0001; it is less than the conventional level of significance of 0.05, and so the result is declared to be statistically significant. The result is represented in Figure 3, which illustrates the difference relative to "2 SE", in this case, 2 SEdiff. The two means are clearly separated by 2SEdiff, and are significantly different.
Figure 3. Representation of the difference between two dependent sample means relative to 2SEdiff.
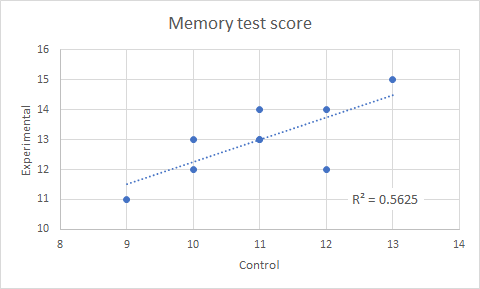
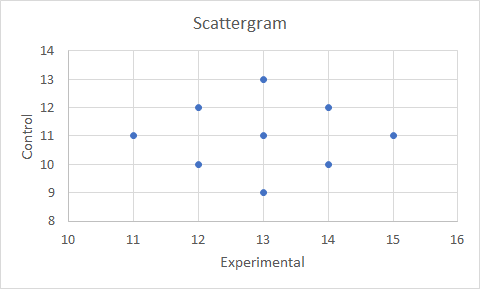
Graph the scattergramIt is always important to graph the data to aid interpretation. In the case of correlated data, the appropriate graph is a scattergram as illustrated in Figure 4. This is an Excel graph that has been annotated with a linear trendline and the coefficient of regression R2. An Excel trendline always relates the values on the Y axis to the values on the X axis; if linear, it comprises a trend equation of the form Y = mX + C. It is therefore useful to arrange the graph with the X axis as the predictor or independent variable (IV) and the Y axis as the dependent variable (DV). If the data is such that there is no good reason to consider one variable as a predictor the trend equation should be omitted, though the trendline remains useful visually. Note that R2 = 0.56 = r2 = 0.752 as expected.
Figure 4. Scattergram of experimental and control memory test scores.
Comparison with independent samplesIf the data is treated as independent samples, we found previously that t = 3.46 with df = 16 and p = 0.003. Importantly, SEdiff there was 0.58, but is 0.29 for the same data treated as dependent samples. We can conclude that a paired samples analysis will better reveal a significant difference, but there is a condition — only if there is an appreciable positive correlation between the samples. Although our t value improved from 3.46 to 6.93, the relevant degrees of freedom decreased from 16 to 8. We should notice, for example, that the α = .05 critical value of t with df = 16 is 2.12 while with df = 8 it is 2.31, so the fewer degrees of freedom set a somewhat higher bar for reaching significance. In general, the size of "appreciable" is not known, but a little experimentation with our data shows that r needs to be at least 0.3 for the smaller SE to offset the smaller df. Conceptually, the reduction of the df in paired samples reflects the "cost" of being able to determine and disregard the variation of data between the subjects separately from the variation to be found within the subjects.
Negative correlationIt may be interesting to note the consequences of a negative correlation between Experimental and Control scores. (1) If it is significant, for example r = −0.75, this tells us that subjects with higher control (baseline) scores tend to have lower experimental scores and, vice versa, that subjects with lower control (baseline) scores tend to have higher experimental scores. Given the presumed context of the experiment, this would be very surprising. To start, we should recall that a correlation of zero would suggest that subjects' memory scores are not consistent between the experimental and control conditions, but vary randomly regardless of the treatment effect which seems to raise scores by 2 on average. By comparison, a negative correlation verges on the absurd since it suggests that subjects' memory scores invert between the experimental and control conditions. Regardless of the treatment effect which seems to raise scores by 2 on average, it suggests that subjects with relatively low scores in one condition show relatively high scores in the other. (2) The negative correlation increases the standard error of the difference between means. If r = −0.75, SE would be √ (0.412 + 0.412 − 2 · −0.75 · 0.41 · 0.41) = 0.76 rather than 0.29, and t would be 2/0.76 = 2.62, p = .03. Still significant, perhaps, but the negative r is most unwelcome. It could make the difference between a result which is very clear and publishable and a result which is marginally significant but probably unpublishable if the negative correlation were revealed. Pause for a moment here and consider: if you were the investigator or advisor, what could be done? You have a thought? No, hiding the existence of the negative correlation is not an acceptable solution, sorry! With most negative correlations (which do tend to be generally unwelcome), the issue may lie with what is being measured or how it is being measured. If so, the fix is to measure and instead use the inverse of one or other (but not both!) of the variables in the correlation. For example, if one of the variables was a memory score where 20 represents "perfect" memory and 0 means a total lack, it could easily be inverted and re-scored by subtracting the memory test score from 20 to now give a measure of "imperfect" memory. In our case, however, any change to the way memory is measured in the experimental data must be applied to the control data; if it is not, then it is no longer the same measure and a paired t-test is not possible. The good news is that the data, amazingly, does suggest an experimental effect. The next section on analyzing change scores provides the necessary solution when the variable cannot be inverted.
Dependent samples change score analysisBecause the data is paired, and because we have the same measure of memory for the experimental and control scores, we can subtract one score from the other to give a change score. Table 4 shows the results. Table 4. Change score for subjects.
We wish to compare the mean change score of 2.0 with the value 0, no change. This in an instance of a single-sample t-test. The change scores have a standard deviation of 0.87, and the SE is 0.29 being s / √n, that is 0.87 / 3. The value of t is given by the difference between the mean change of 2.0 and zero, ie 2, divided by the SE, 2 / 0.29, being 6.93 with df = 8 and p = 0.0001. This comparision is illustrated in Figure 5. The mean change score is represented by a white cube, and the fact that the data comprises change scores is represented by a half cylinder protruding from the cube.
Figure 5. Representation of the difference between the mean change score, 2, and the value of interest, 0, relative to 2SEdiff, 0.58. We have seen exactly these values earlier, where the correlation was 0.75 between the experimental and control data. The SE of the difference between the two dependent means of experimental and control was found to be 0.29, yielding the same t, df, and p. It turns out that a dependent samples t-test of the difference between the sample means is identical to a single sample t-test of the mean difference or change score.
Change score and negative correlationWe examine the change score analysis of our problem data which had a hypothetical negative correlation of −0.75. Table 5 shows what the data might look like if r = −.75. Table 5. Memory scores for experimental and control data with r = −.75 and change score.
For the change score, SE = 0.76 and t = 2 / 0.76 = 2.62, df = 8, and p = .03. This is identical to the earlier result of a dependent samples t-test of the difference between the sample means with negative r = −.75. This time a change analysis presented like Table 4 is clear and publishable, and only an experienced data analyst or statistician will think to wonder what is hiding behind the curtain. The comparison of the mean change score with zero is illustrated in Figure 6 in the case of the negative correlation and the consequently larger SEdiff.
Figure 6. Representation of the difference between the mean change score, 2, and the value of interest, 0, relative to 2SEdiff, 1.52. As an investigator it can be tempting to continue the analysis of the change scores by asking questions such as, "Is the change in memory score as a result of treatment related to the baseline subject's memory score?", or "Is the change in memory score as a result of treatment related to the subject's memory score following treatment?" These appear to be interesting and meaningful questions. Let's see. Table 6 shows the correlation between change score and control score, and between change score and experimental score. If you like, pause for a moment here and consider: what do you expect to see? Zero correlations? Positive correlations? Negative correlations? Almost perfect correlations? Table 6. Experimental, control, and change score correlations.
We can see that the change score correlates r = 0.94 with the experimental score, and r = −.94 with the control score. Let's "interpret" these correlations. For the experimental score and the change score, r = 0.94, and this suggests there is an almost perfect positive relationship such that higher memory test scores following treatment are associated with larger changes in memory test scores, and vice versa. There is an almost straight-line relating change score to experimental score, where it seems that the better the subject's memory the better the effect of treatment, p < .0001. Sadly, we know this is nonsense. For the control score and the change score, r = −0.94, and this suggests there is an almost perfect negative relationship such that higher memory test scores at control are associated with smaller changes in memory test scores, and vice versa. There is an inverse almost straight-line relating change score to control score, where it seems that the better the subject's memory the worse the effect of treatment, p < .0001. Well, there is something in that, because experimental and control scores do correlate negatively, r = −.75, but mentioning this finding would blow your cover and your rejection letter would follow promptly. There are four points to take away here. (1) The t-test analysis of change scores is entirely legitimate and answers the question perfectly well — is the average change score significantly greater than zero? This is the same as the question, is there an experimental effect? And it is the same as the question, is the experimental group mean significantly different from the control? (2) For a change score S given by E − C, never correlate E or C with S — the interpretation of the resulting correlation will be problematic. The reason is that "half" of the S score is due to E, and the other "half" of the S score is due to −C. This means that, by definition, S and E must correlate, and S and −C must also correlate negatively (§2). (3) Be suspicious of any correlation involving a change score S arising from E − C. Be sure to review the summary statistics of and correlations with E and C themselves. Because "half" of the S score is due to E, for example, S necessarily correlates with any other variable that correlates with E. More problematic is that S necessarily correlates negatively with any other variable that correlates with C. (4) The data can always be analysed using an independent samples test, which is equivalent to assuming r = 0. A knowledgeable reviewer will be suspicious, however. §2. Let's check whether the warnings about correlating any variable with a change score S = E − C apply if E and C are uncorrelated, ie their r = 0. Again, pause for a moment here and consider: what do you expect to see? Table 7 shows the data re-arranged so that E and C are uncorrelated, and Figure 7 illustrates the scattergram. Table 7. Experimental, control, and change score correlations. Experimental and control data have r = 0.
Figure 7. Scattergram of experimental and control memory test scores with r = 0. Even though E and C are uncorrelated, r = 0, the change score S still correlates strongly, r = 0.71 with E, and r = −0.71 with C. As observed earlier, S owes "half" its value to E and "half" its value to −C. This always applies, though the effect is stronger with increasing negative correlation between E and C scores, and is weaker with increasing positive correlation between E and C scores. It may also be useful to notice the SE of the change score mean which is 0.58 — this is √(0.412 + 0.412) when r = 0, and is the same as the value found earlier in the analysis of two independent samples. Finally, we may be tempted to ignore the suggestion not to correlate a change score with anything, and certainly not with E or C. It is very tempting to correlate the change with the baseline or control condition, and to ask whether change is related to baseline — do subjects with higher baseline scores tend to change more, which would be shown by a positive correlation, or do they tend to change less, shown by a negative correlation? It is usual to consider change as a change from baseline, which means structuring the change score as S = E − C. Other things being equal, it is likely that an experiment will find that the average E scores are higher than the average C scores, meaning most of the change scores are positive, and that is desirable. But we know that S necessarily correlates with −C, that is, negatively, which means we are halfway to the forced (and false) finding that subjects with higher baseline scores tend to change less. Just don't do this. Instead, interpret the correlation between C and E, it tells us whether or not higher E tends to be associated with higher C, and this is all we can know from the data.
Dependent samples variance analysisRemembering the reason for the dependent samples design, which is that different subjects will have rather different scores but particular subjects will have a similar scores, we seek to identify and then remove the variation due to different subjects, leaving the variation within the subjects as the basis for estimating the standard error of the mean difference between the control and experimental data. The procedure is to calculate the average score of each subject and the variance of these average subject scores. The variation of the average subject scores represents the variation shown from subject to subject in their memory tests in the experimental and control conditions. Table 7 shows this. Table 7. Memory scores for experimental and control data and subject averages, r = 0.75.
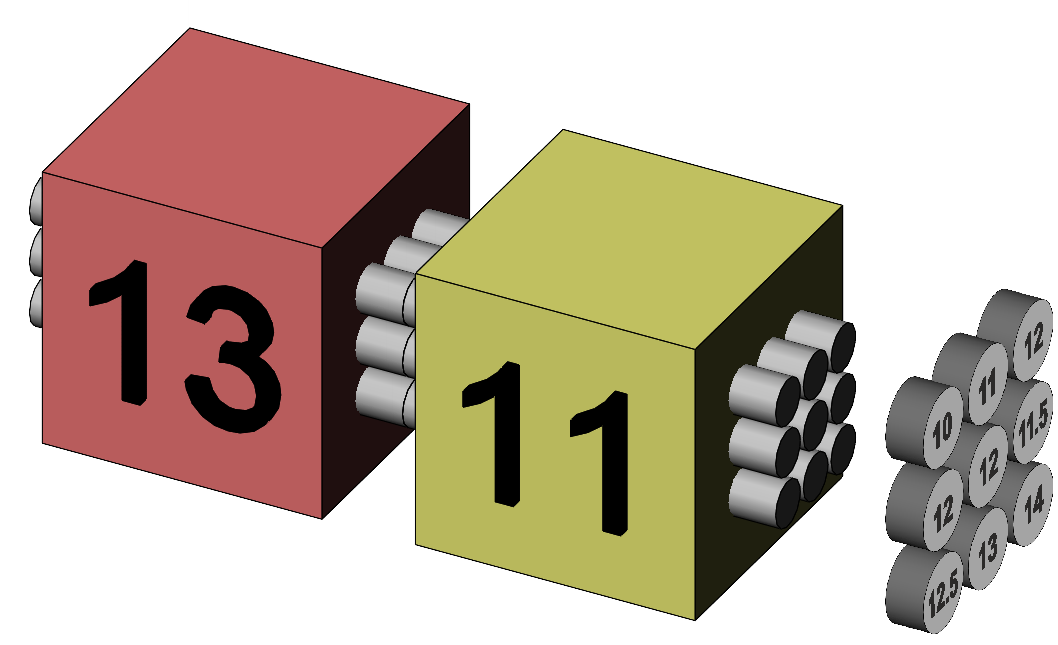
The construction of subject average scores is illustrated in Figure 8.
Figure 8. Representation of the subject average scores as based upon the subject scores in each sample. Conceptually, the variation of the scores in a group such as the experimental group comprises the variation due to differences between the subjects in general plus the variation that the subjects show within the experimental group itself. Our procedure is to remove the variation due to subjects in general from their experimental and control group scores to leave within-subjects variation. Variation is identified here with the sums of squares, SS, calculated by multiplying a variance by its degrees of freedom. After removing the SS due to subjects in general from each of the treatment groups, we also remove their df, a process called paritioning. We then may calculate the resulting variances by dividing the partitioned SS by the relevant partitioned df. The experimental group SS is 12. Subtracting subjects in general SS, 10.5, from the group SS yields the within-subjects SS (also called the residual SS) for that group, = 12 – 10.5 = 1.5. We do this for the control group and add up the resulting SS, 1.5 + 1.5 = 3, to give the total SS within subjects. The df are partitioned by removing the df of the subjects in general, 8, from the total df for the groups, 16, to yield the within-subjects df, 16 - 8 = 8. The df of the subjects in general is called the between-subjects df. Using the calculation for a variance as SS / df, the within-groups variance is thus 3 / 8 = 0.375, and the between-groups variance is (10.5 + 10.5) / 8 = 2.625. We treat the within-subjects variance as a better measure of the variation we expect to see in the group means, and use it to calculate a better estimate of the standard error of the difference between the two group means. The within-subjects standard deviation is √0.375 = 0.61. The SE of a group mean based upon within-subjects variation is given by s / √n = 0.61 / 3 = 0.204, and SEdiff between two means = √(0.2042 + 0.2042) = 0.29 (§3). We have see this SE value twice before! It is identical to the SE derived from the change score analysis. It is also identical to the SE derived from the correlation analysis. We can finish off the analysis by calculating the t-test for the difference between the group means, t = diff between means / SE of the diff between means = (13 – 11) / 0.29 = 6.93 with df = 8 as seen in the change score analysis and the correlation analysis. Table 8 provides a summary of the variance analysis (§4). The F ratio has been calculated as MS(Means) / MS(Within subjects) = 18 / 0.375 = 48, with df 1 & 8. We immediately notice that √F = 6.93, the t score we've seen before, or equivalently that t2 = 48. Table 8. Variance analysis summary.
§3 Note that the SE for the difference between two means is here given by √(0.2042 + 0.2042) with no correction for any correlation. This is because the individual group mean SEs have already been adjusted for the correlation when the variance of the average subject scores was subtracted from the total variance. We can check this. We can correlate the average subject score, A, with the subject's experimental score E, and obtain r = 0.935; the same holds for the correlation of A with C. This is a high value of the correlation coefficient and is explained by the fact that "half" of A is given by E and "half" by C, because A = (E + C) / 2. Actually, it is more than "half" because E and C themselves are correlated with r = 0.75. We square the correlation to see exactly how much variance in E or C is accounted for by the average subject score A; 0.9352 = 0.875. The variance of E is 1.5, 87.5% of that is 1.31, the same is true for C, and so the variance in E and C added together which is accounted for by A is 2 · 1.31 = 2.625. We have seen that value before, it is the between-subjects variance. The within-subjects variance is the variance that is unaccounted for by A, being 3 − 2.625 = 0.375. So the within-subjects variance used to calculate the SE of the difference between the means is the variance which is left over when the variance due to the correlation between E and C is removed. No further correction for the correlation is needed, it is already done. §4 The conceptual explanation for the analysis is that we remove the variation due to subjects in general from the group scores to leave the within-subjects variation. To do this we calculate the variation due to subjects in general as the variance of the subjects' mean scores. Another way to arrive at the variation due to subjects in general is to calculate the portion of the variance shown by the group scores which is accounted for by the subjects, and that is given, conceptually, by the correlation of the subjects' scores in one group with their scores in the other. The average variance of each of the group scores is 1.5 for our data. The correlation between the scores is 0.75 and so we may consider that 0.75 times 1.5 represents the variance due the subjects, 1.125, and when subtracted from 1.5 yields the residual or within-subjects variance, 0.375. This is exact for our data where we see that MS(within subjects) = 0.375, but this is only because the variance of the group scores is the same in each group. In general, the calculation is approximate because the groups will generally show different variances.
SummaryConsider two dependent samples E and C, made up of n pairs of data items. The probability of observing a difference D between the means of E and C by chance may be appropriately modelled by the t distribution where the test statistic t = D / SEdiff is referred to the t distribution with df = n − 1. The value for SEdiff may be obtained in three different ways which all yield identical results. (1) One way is to consider the correlation r between E and C, when a smaller SEdiff results when r is positive by comparision with a test that treats the samples as independent. By comparison with an independent samples test, a dependent samples test has fewer degrees of freedom and consequent loss of power, implying that r should be "appreciable" to compensate for such loss. (2) A second way is to consider and analyse the change score S = E − C, with a resulting t-test that is identical and simple to both calculate and interpret. However, further analyses involving any correlation of the change score S with E, C, or indeed any other variables are problematic and should be avoided. (3) A third way, which forms the basis of the analysis of variance for dependent samples, is to consider the variation of the average subject scores and to subtract that "between-subjects" variation from the total data variation to yield a "within-subjects" variance that is the basis for the SE. Next: Fundamentals of the one way anova and repeated measures.
Using ExcelExcel provides a function T.TEST(Array1,Array2,Tails,Type) to calculate a two-sample t-test, but it actually calculates a probability. In order to obtain the value of t for reporting, the given probability must be used in Excel's inverse t function. The T.TEST function has four arguments. Array1 and Array2 are the sample data. Tails is always 2 for the analyses we will do. Type refers to whether the two samples are dependent, Type is 1, or independent, and if independent whether to assume homoscedasticity, Type is 2, or to assume heteroscedasticity, Type is 3. The result of T.TEST is a probability, p, so to find out the actual value of t use the function T.INV.2T(p,df). It may be useful to know the critical t for a given df and α. Calculate this using T.INV.2T(α,df).
|
|
©2025 Lester Gilbert |