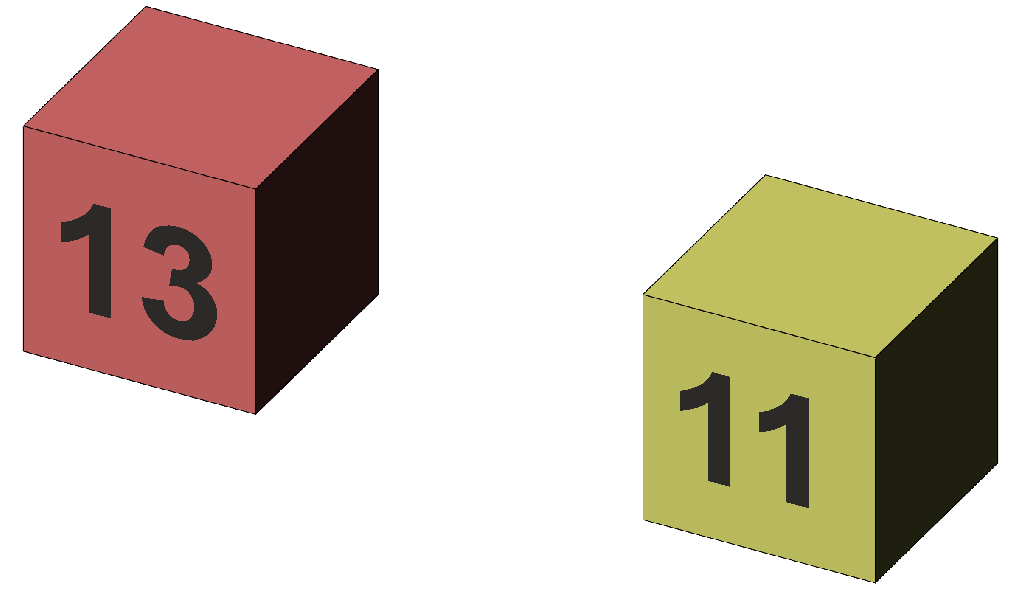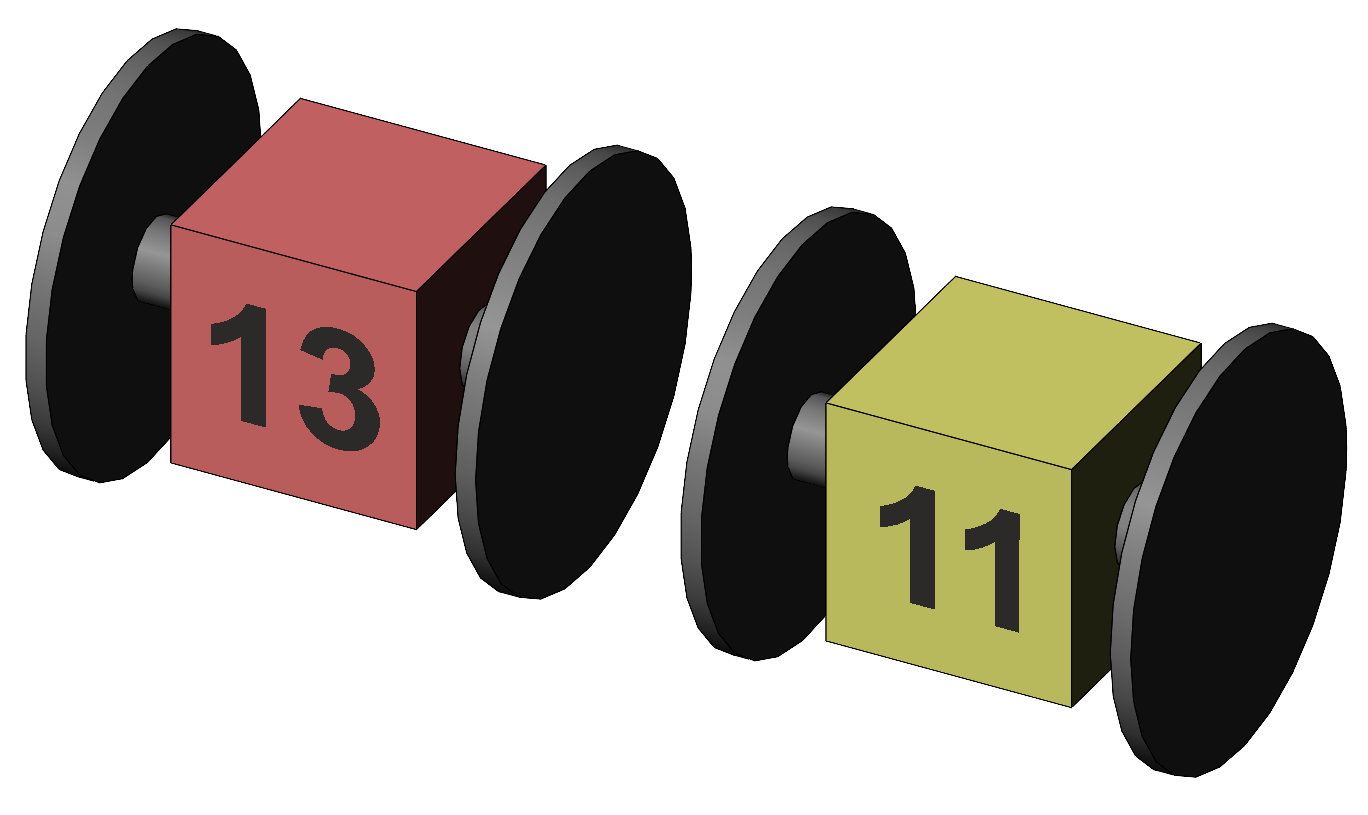![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
Previously: The basics of one sample and what you need to know about testing the difference between a (single) sample mean and some specific value. This page is concerned with testing the difference between two
sample means, where each sample comprises a different group of subjects, and its
connection with correlation and regression. A group of 9 subjects undertake an experimental treatment and are then scored on a memory test. A second control group of 9 subjects take tea and biscuits and are then scored on the same memory test. The data is shown in Table 1, where each subject is called a case. Notice that these two samples are independent — they consist of different subjects. Table 1. Memory scores for experimental and control subjects.
This experiment is representative of the "gold standard" for simple experiments – an experimental group undertake a treatment while a control group undertake a "neutral" activity and both are then tested on a relevant measure. The question here is whether the treatment improved the memory of our subjects compared to a control. The experiment is represented in Figure 1.
Figure 1. Representation of the comparison between the means of the experimental (red) and control (yellow) groups.
Testing the difference between two independent sample meansAn answer is given by comparing the mean memory score of the experimental group with that of the control. Table 2 shows the descriptive statistics of mean, standard deviation, sample size, and standard error of the sample mean. Note the change of notation for sample sizes. The total number of data points is N = 18 (N in upper case), while the sample sizes are n = 9 (n in lower case) for the experimental group and n = 9 for the control group. Table 2. Descriptive statistics for experimental and control subjects.
It looks like the experimental group mean score is 2.0 higher than the control, but is this "real" or could it be a chance difference? One approach might be to consider the SE of each mean, construct their corresponding 95% confidence intervals, and decide whether any interval includes, or does not include, the other mean. If included, their difference would not be significant. We develop this approach to make it visually and conceptually useful, but will use a different and more exact approach afterwards. We can make a simple visual and conceptual comparison between two means by representing a ±1SE interval for each mean, and then determining if their intervals overlap. If the intervals do not overlap, this suggests that the two means are at least 2 SE different, and suggests that a more exact approach is likely to find the difference significant. If the intervals do overlap, a more exact approach is unlikely to find significance. The key component here is our "2SE" rule of thumb. For our data, experimental and control group means both have SE = 0.41, and so 2SE = 0.82. The difference between the means is 13 – 11 = 2, and that is certainly larger than 2SE. Figure 2 illustrates the lack of overlap between the ±1 SE intervals around each mean.
Figure 2. Representation of the comparison between the
means of the experimental (red) and control (yellow) groups using confidence
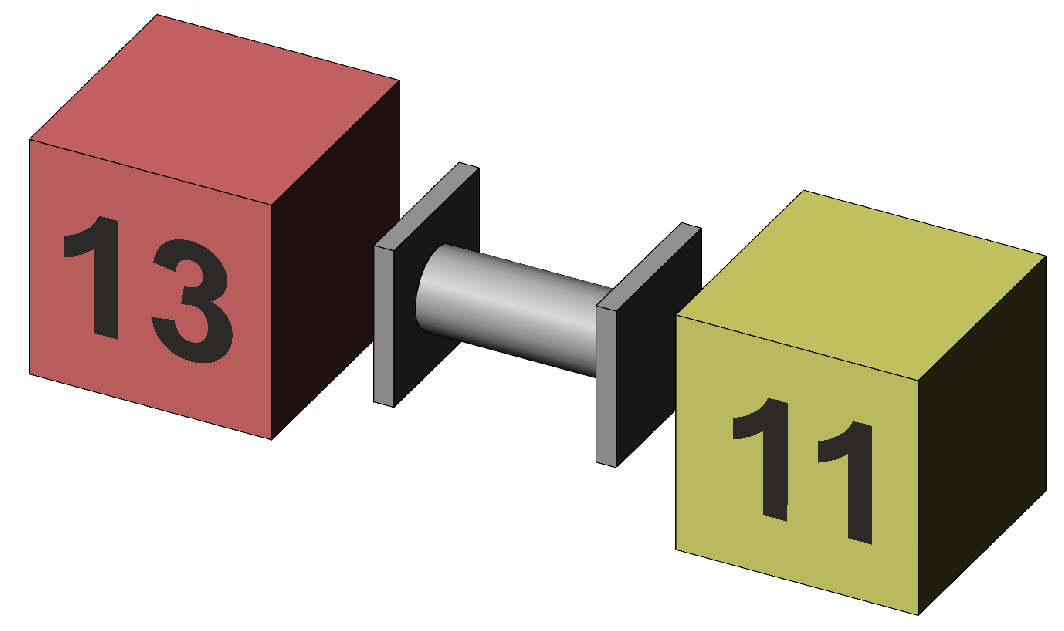
intervals of ±1 SE. There are two issues with the precision of the 2SE rule of thumb. We have seen one issue already — depending on the degrees of freedom, the critical value of the number of SEs in a difference needed to reach significance can be rather different from 2; for small N around 6 or 7 it is 2.5, dropping to 2.2 for N around 12 and then to 2.1 for N around 20. The second issue is that the variability of a difference between two means is larger than the variability of one or other mean. One of the features of the variance as a measure of variability is that it is additive — the variability of the sum of or difference between two items of data is given by the sum of their variances (§1). Where the items of data are two means, their individual variances are SE2 and so the variance of their difference is SE2 + SE2 (as is the variance of their sum). The standard error of their difference is given by the square root, SEdiff = √( SE2 + SE2 ) = √(0.412 + 0.412) = √(1.67 + 1.67) = 0.58 for our data. This is a value that is quite different from the SE of either mean. In the same way that SEdiff is derived by adding two variances together, the degrees of freedom for SEdiff is given by adding up the df for the two samples — df(SEdiff) = df(Experimental) + df(Control) = 8 + 8 = 16. We can now be more exact. The probability of observing a mean difference of 2.0 by chance is given by calculating the number of SEdiff in that difference, t = difference / SEdiff, and referring to the t distribution with df appropriate to SEdiff. For our data, t = 2/0.58 = 3.46 with df = 16, and we find p = 0.003. We note the critical value of t with df = 16 is 2.12. We may calculate the "critical difference" for use in the illustration of Figure 3, Crit t · SEdiff = 2.12·0.58 = 1.23, showing the difference between the two means visually.
Figure 3. Representation of the difference between the
means of the experimental (red) and control (yellow) groups using Crit t · SEdiff of the
difference between the
sample means. §1 If you are refreshing your understanding of statistical data analysis, you'll probably know that the variance of the sum of or difference between two items of data is the sum of their variances only if the data is independent and uncorrelated, and this is the situation here. In the page on Two dependent samples we see the complete picture for data that is correlated.
AssumptionsNote that our two samples are of equal size. This is known as a "balanced" experimental design, and is particularly desirable because the statistical theory we've just used assumes this. There are various techniques which permit the comparison of the means of unequal samples, and these techniques are found as standard in statistical packages. We will not cover them here. Note also that the statistical theory also assumes that the population variances are equal. This assumption is called homoscedasticity. There are various techniques which permit the comparison of the means of samples with unequal variances, and again these are found as standard in statistical packages. Most packages provide for a test of homoscedasticity and provide for options in the case of significant heteroscedasticity. Finally, note that referring a test statistic to the t distribution assumes that the mean difference is distributed as t. If N is large, we could refer the test statistic to the normal distribution, when we assume that the mean difference is normally distributed. What is crucially important about this assumption is: There is no assumption that the data items are normally or t- distributed. Importantly, what is being assumed is that it is the mean difference which is normally or t- distributed, and the Central Limit Theorem (CLT) tells us that this is the case for increasing N no matter the shape or distribution of the data items themselves. A value of N > 30 is taken by convention to be large enough for the CLT to apply regardless (§2). Note that in these and other calculations on this page there may be rounding errors; the values reported here have been rounded to 2 decimal places, and calculations made with the rounded values may show minor disagreement in the second decimal place. §2 For N smaller than 30, well, it would be wise to check that the histogram of the data items is "humped" and that there are no extreme values in the tails. Whether the histogram shows any skewness is less important than whether any tails show extreme values, and this is more important than whether the histogram is tightly humped (leptokurtic] or slightly humped and widely spread out (platykurtic, but without extreme outliers). The t-test (and other associated tests) are considered robust in the absence of extreme outliers. Outliers can be treated by winsorizing, curtailing, clipping, trimming, or truncating. Certain raw data sets, even with N > 30, may be usefully transformed to a more "humped" shape; in particular, this applies to data dealing with time — arrival time, departure time, time to first fault, and similar — which typically follow a Poisson distribution.
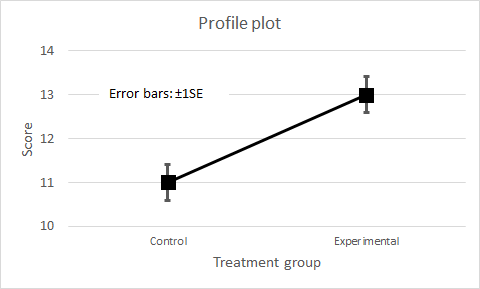
Profile plotAlways draw a graph to aid interpretation. Where the question concerns the difference between means, the appropriate graph is a profile plot. It is a line graph of the group means, with error bars of plus and minus one standard error. It may be that other profile plots show error bars which are ±2SE, but ±1SE has the visual advantage that, if the bars do not overlap, the means are at least different by 2SE, which suggests a significant difference.
Figure 4. Profile plot of group means.
Testing the correlation between treatment and scoreThere is another approach to the question whether the treatment improved the memory of our subjects compared to a control. We lay the data out as in Table 3, where there is a dummy variable, "EvsC", which codes whether the case and the score belongs to the experimental group, EvsC = 1, or to the control group, EvsC = 0. Note that the coding here could be any two distinct values such as 1 and 2; but choosing to code the baseline (control) as 0 and the treatment as 1 has benefits when the results are interpreted. Table 3. Memory scores for experimental and control subjects.
An answer to the question whether the treatment improved the memory of our subjects is given by correlating the memory scores with the "dummy" variable EvsC which codes the source of the score as either experimental or control. A significant correlation suggests a significant association between memory score and EvsC, while an insignificant correlation suggests no association. Table 4 shows the descriptive statistics of mean, standard deviation, sample size, and correlation coefficient. Table 4. Descriptive statistics for EvsC and Score variables.
Note the interpretation of the correlation — it is positive, so the higher the EvsC, the higher the score. Hence, the control group with EvsC = 0 is associated with lower memory scores, while the experimental group with EvsC = 1 is associated with higher memory scores. The significance of the correlation can be tested by converting r to a t score using the formula t = r / √( (1−r2) / df) with df = N−2 (§3). For our data, this yields t = 3.46 with df = 16 and p = 0.003, highly significant We have of course seen this exact value of t before. The t-test for the difference between the experimental and control group means gave t = 3.46 earlier. Correlating a dummy variable of treatment with the scores variable gives a result identical to the usual t-test of the difference in scores between control and experimental groups. The association between two variables can be usefully presented as a linear regression, where we ask whether one variable can be significantly predicted by the other. For our data, we could ask whether the treatment predicts the memory score and so we would regress the dependent variable of memory score against the independent variable EvsC. The results of such a regression are given in Table 5 showing the regression prediction equation and associated statistics, and in Table 6 showing the anova summary associated with the regression. Table 5. Regression coefficients.
The prediction equation is Score = 2 · EvsC + 11. The value of the B weight, 2, is the difference between the score means when EvsC = 0 and when EvsC = 1. This difference has a standard error of 0.58, and this is identical with the value found earlier for the standard error of the difference between the experimental and control group means. The t-test for Beta (standardised value of B) is, as already seen, identical with the earlier t-test for the difference between the experimental and control group means. The value of the constant, 11, is the score mean when EvsC = 0. Table 6. Regression anova summary.
We note that p value for the F is .003, the same as for the t-test. We also note that t2 = 12, the same as F, alternatively, that √F = 3.46, the same as t. The interpretation of a significant regression F ratio is that the independent variable, EvsC in our case, explains a significant proportion of the variation in the dependent variable, in our case the memory score. Note the careful wording; while we know that variation can be measured by variance, the claim in the situation of a regression anova is that the correlation between the IV and the DV explains variation, not variance. The measure of variation we need to use here is given by the sums of squares. We see that the total SS of the memory scores is 42, of which the IV (EvsC) accounts for 18. The proportion of the SS accounted for by the IV is 18 / 42 = 0.439 or 42.9%. This is the value of r2, 0.652 = 0.439. The residual SS is 24, and its proportion of the total is 0.571, which is the value of 1 − r2 (§4). This is the basis for a common interpretation of the correlation coefficient — its square represents the proportion of variation one variable accounts for in the other. The residual MS of 1.5 is also known as the error MS or error variance. It is also a value we have seen previously, although not explicitly. MS(Error) is the average variance of the groups which make up the data. The standard deviation for the experimental group is s, 1.22, and its variance is s2, 1.5. For the control group, s is also 1.22 and its variance also 1.5, where it so happens that s and variance are the same for both groups. The average group variance is 1.5, being the value of MS(Error) also called MS(Residual). Using correlation and regression to analyse the memory score data for our independent experimental and control groups is identical with using a Student's t-test for the same purpose. It is an effective and preferred analysis within certain contexts, mainly medical, where practitioners are more accustomed to using correlations. The major drawback with the technique is that while it is easily interpreted with two groups, it is much more difficult to interpret when it is generalized to three or more groups. Orthogonal polynomials are required with multiple dummy variables. The technique does have a conceptual value in illustrating that the dummy data does not need to be "normally distributed" — the EvsC dummy variable is nothing like normally distributed, see the scattergram of Figure 2 — yet it can permit interpretation as meaningfully as a t-test. §3 You'll not usually see the formula to convert r to t presented as "t = r /√( (1−r2) / df)". Instead, you'll see "t = √(N−2) · r / √(1 − r2)" which might be mathematically better formed but which obscures the formula's structural components. Remembering that F = t2 we can re-write our first formula as F = r2 / ( (1−r2) / df). We then remember that F is a ratio of two variances, and in this particular case has degrees of freedom = 1 & df. We can now re-write our formula showing the F as a ratio of variances "r2 / 1" and "(1−r2) / df". §4 Writing F as a ratio of variances "r2 / 1" and "(1−r2) / df" allows the identification of "r2 / 1" as MS(Regression) = SS(Regression) / df(Regression), and "(1−r2) / df" as MS(Residual) = SS(Residual) / df(Residual). This corresponds to the regression anova summary.
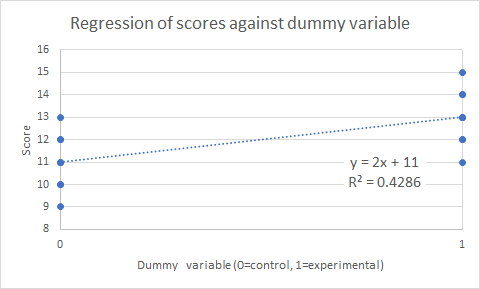
Graph the scattergramIt is always important to graph the data to aid interpretation. Figure 5 is an Excel scattergram that has been annotated with a linear trendline and the coefficient of regression R2. The prediction equation Y = 2X + 11 confirms what we saw earlier. Note that R2 = 0.43 = r2 = 0.652 as expected.
Figure 5. Regression scattergram of scores against EvsC dummy variable. SummaryThe question of the effectiveness of a treatment (or any other factor of interest) depends on the question, "Compared to what?" The "gold standard" compares a treatment group to a control group. The experiment is balanced if experimental n = control n, and this is desirable. Consider two samples of data items, E and C. The probability of observing a difference D between the means of E and C by chance may be appropriately modelled by the t distribution where the test statistic t = D / SEdiff (SEdiff is the standard error of the mean difference) is referred to the t distribution with the df of SEdiff. Remarkably, exactly the same result is given by constructing a dummy variable representing group membership and correlating or regressing group membership with or against the score. Next: Two dependent samples, testing the difference between two sample means from the same subjects and its connection with correlation and regression.
Using ExcelExcel provides a function T.TEST(Array1,Array2,Tails,Type) to calculate a two-sample t-test, but it actually calculates a probability value, not a t value. The T.TEST function has four arguments. Array1 and Array2 are the sample data. Tails is always 2 for the analyses we will do. Type refers to whether the two samples are dependent, Type is 1, or independent, and if independent whether to assume homoscedasticity, Type is 2, or to assume heteroscedasticity, Type is 3. The result of T.TEST is a probability, p, so to find out the actual value of t use the function T.INV.2T(p,df). For balanced data, the Type 2 and Type 3 t-tests are identical. For unbalanced data, the Type 3 test result is more conservative, that is, the t value is smaller and the p value higher than for a Type 2 test on the same data. It may be useful to know the critical t for a given df and α. Calculate this using T.INV.2T(α,df).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
©2025 Lester Gilbert |