![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
Previously, introduction to Multivariate Anova, Multivariate Visual Error Oval, Multivariate Anova part 2, and Multivariate Anova Part 3. We consider some further points here in the multivariate analysis of variance. Well, just one at the moment, but I expect to add to this page when other interesting points occur.
Homogeneity of covarianceWe have seen that the multivariate anova considers the measures taken together and uses the observed correlation between the measures in computing the test statistic for the differences found between the centroids of the groups. One of the assumptions of the multivariate analysis is that the observed correlations in the groups are samples from the same population and that variation in these observed correlations is merely due to random sampling error. This is an assumption of homogeneity. The Manova computes and uses what is effectively an average of the group correlations based on this assumption, and so it is usual to test this assumption when carrying out a Manova. The test is "Box's M test", named after the statistician George Box (§1, search Wikipedia), and should be provided by, or requested from, any statistical application that offers the Manova. If the test is significant, there are at least two points to consider. (§1) Box's catch phrase was, "All models are wrong, but some are useful". Certainly a valuable and important observation for any investigator.
Significant M — fixing heteroscedasticityIf you have not already plotted a scattergram and trend lines for each group, well, now is the time to do it so you can see what the significant Box M is telling you, which is that the trends of the, er, trend lines are significantly different — that is, the correlation that each trend line represents is different in each group. It may be that you have already calculated the correlations in each group and have them nicely tabulated, for example, r = 0.23 between A and B in Group X, and r = 0.67 in Group Y. Your Box M says there is significant heteroscedasticity of covariances. Are you worried? Unless you have been investigating A, B, X, and Y for the last 20 years, you probably have no real idea. So plot the correlations as trend lines on a graph to better judge if the divergent trends worry you, or if they are nothing to be too concerned about. We'll see divergent trends in an example shortly. OK, the divergence in trend lines worry you, or the significant Box M frightens your Journal Editor. What can you do? Homogeneity and heteroscedasticity are concerns in the univariate analysis of variance, for example, but there the concern is for homogenous group variances. This is because the within-group variances are pooled in order to better estimate the population variance. If these variances are not similar, that is, if they show heteroscedasticity of variances, there are four approches to deal with the issue. 1. Attempt a data transformation to restore homogeneity. This often works for time-based data which is usually Poisson-distributed rather than Gaussian (normal). This might work for multivariate data. 2. Reduce the degrees of freedom for a more conservative test of the reported statistic. The necessary reduction parameter is well-understood in the repeated measures anova, where Mauchly's Test of Sphericity tests the covariance matrix. It's lower bound for the Factor degrees of freedom is 1 and for the error df is 1/(p-1), where p is the number of groups. A similar lower bound might find application in reducing the F ratio's df associated with one or other of the multivariate tests such as Pillai's Trace, and is a promising approach if another approach doesn't seem to work. 3. Calculate a revised value for the standard error, equivalently, a revised value for MS(error), based on "heteroscedasticity-robust standard errors". There are 5 flavours of HC-robust SE, and SPSS will calculate one or other of them for you in a univariate anova; by default, it calculates HC3 if asked. Not currently available for a multivariate test. 4. Better estimate MS(error) by "bootstrapping". SPSS will do that for you if asked. Bootstrapping draws a large number, >1000, of random samples from the data and uses the result to estimate the sampling distribution of the statistic of interest, usually a mean or variance. This allows an estimate of the p value for some hypothesis about that statistic (for example that it is larger than 0, or different from some specified value) that does not rely on or require any assumptions based upon some theoretical distribution such as the normal or t distribution. The SPSS bootstrapped multivariate test doesn't so much "fix" heteroscedasticity of covariance as work around it in estimating the p value for the multivariate test. But before "fixing" the significant heteroscedasticity of covariances, check that this is desirable or even possible. And then, see if it is needed.
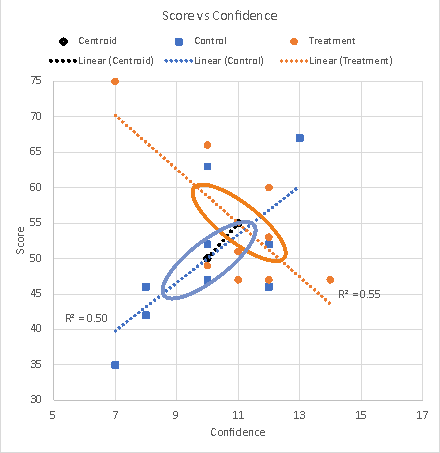
Significant M — no fix desirable or possibleWe recall the (in)famous inconsistent group correlation from the Multivariate Anova part 2 page, where one group shows a positive correlation between the measures, and the other shows an opposite, negative, correlation. The data has r = 0.71 in the Control group and r = –0.74 in the Treatment group. The scattergram is shown as Figure 6 in the Multivariate Anova part 2 page, and it is reproduced here as Figure 1.
Figure 1. Scattergram with Control group r = .71, Treatment group r = – .74 The significant Box M statistic is shown in Table 1 below for the data of this example.
The significant Box M is telling us what is blindingly obvious if we have drawn the scattergram and the trend lines (but which might be a complete mystery if not) — the correlation of Confidence with Test score in the Control group is completely different from the correlation in the Treatment group (§2). (§2) The Box M test provides us with a test statistic for a research hypothesis which we might have had (and, given the results, which we very quickly decide that we had all along, of course we did), to the effect that the elixir works in a different way from a conventional hydration using plain water. There is no fix possible for this significant Box M, but more importantly, no fix is desirable. The data is telling us exactly what happened in our experiment, and the Box M test is telling us that it is significant — the result of the Treatment group participants drinking the elixir was that their Test score increased in almost exact proportion to the decrease in their Confidence, in complete contrast to the result of the Control group after drinking coloured water which was that their Test score increased in almost exact proportion to their *increased* Confidence. There is a possible downside, of course, to our finding of such an unexpected and very interesting result, and that is whether the multivariate test can be trusted. For the data shown above, Pillai's Trace was not significant, p = 0.37, but in another context it might be. The difficulty with trusting the multivariate test, of course, is that it is based on the assumption of heterogeneity of covariance, and that assumption very clearly does not hold here.
Significant M — do we care?We recall the exploration of the deep connection between regression and the multivariate anova in Multivariate Anova Part 3 where we saw that a (very unusual) linear regression yields a result which is identical to that from a multivariate anova. We took what is usually an IV, Group membership, and set it as the DV; and we took two measures which would usually be DVs, Confidence and Test score, and set them as the IVs in a regression. This is a conceptually difficult arrangement, but computationally it is the same as a multivariate anova. The point is that the regression does not have the assumption of homogenous covariance that is found in the multivariate anova. So we can trust our multivariate test even with a significant Box M (§3). (§3) Note that this trust is unlikely to extend to the reviewer of your report. If so, you will need to report your analysis as a regression and cross your fingers. And no, don't send them the link to this page, nobody will thank you for it.
| ||||||||||||
|
©2025 Lester Gilbert |