![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
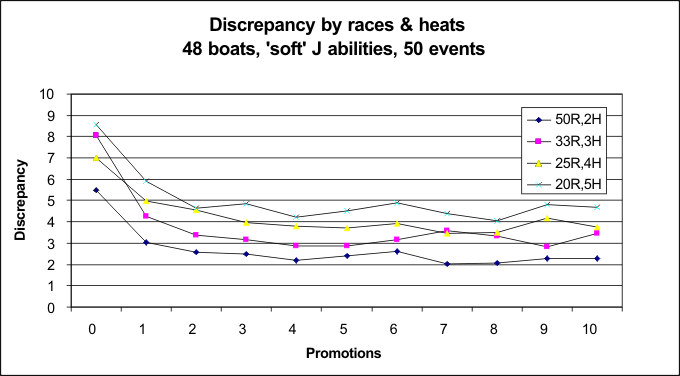
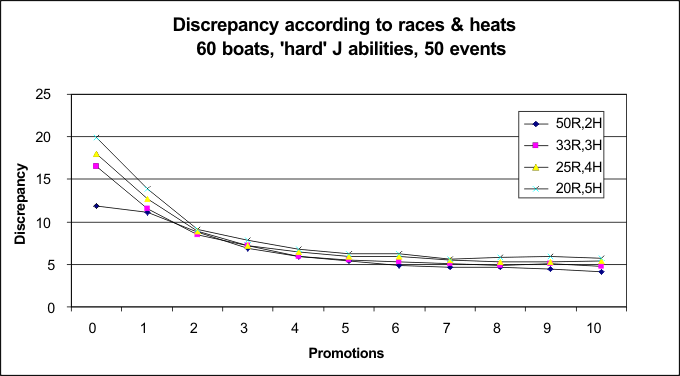
20 races with two heats, or 10 races with four heats? Two runs of the simulator looked at this question when there were 48 boats with 'soft' J spread of abilities, and when there were 60 boats with 'hard' J spread. In each, there were 50 races of 2 heats, or 33 races of 3 heats, or 25 races of 4 heats, or 20 races of 5 heats. Of course, in order to get 2 heats in a fleet of 60 boats, somewhat more than 20 boats raced in each heat, so the results are intended to illustrate probable outcomes in an ideal world... Conclusions are that more races always give lower discrepancy values, rather than more heats. This is particularly true when the boat abilities of the top boats are closer together. If the abilities of the top boats are well above the majority of the fleet, the good boats come through regardless.
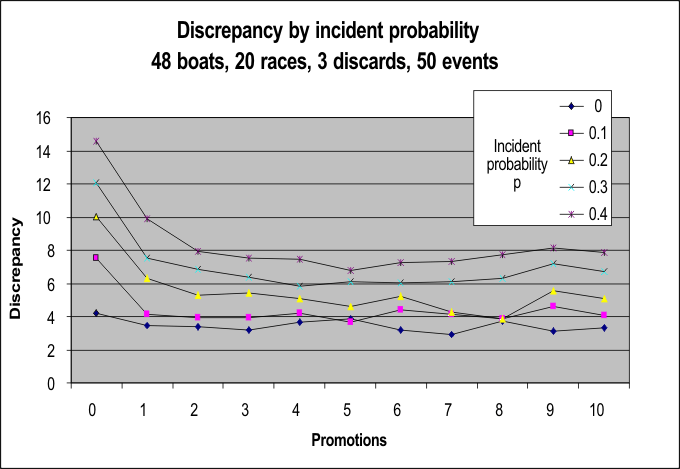
Fewer incidents during heats? It is probably stating the obvious, but the more incidents there are, the more variable the race and event outcome. Perhaps less obvious is that this remains true, pretty much regardless of the number of boats promoted in each heat, as long as at least 2 or 3 are promoted...
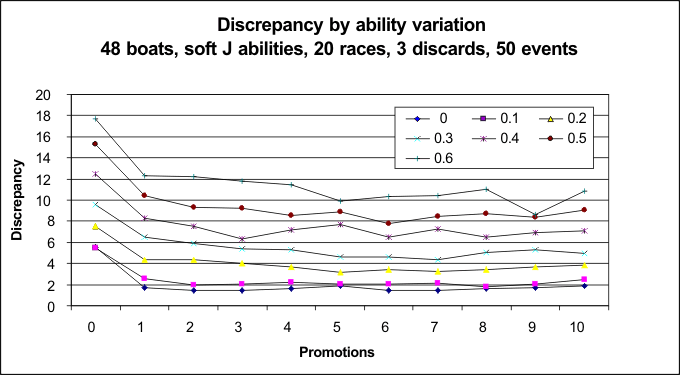
Just to complete the picture, here is the graph which results if we vary the race-by-race random variation in boat ability. When there is no ability variation (0), only the random incidents give rise to discrepancies, and the discrepancy score is the lowest of all, oscillating just under 2. With high ability variation (0.6), the discrepancy score oscillates around 10 or 12. Interestingly, provided there is at least one promotion, the pattern is the same, regardless of race-by-race ability variation.
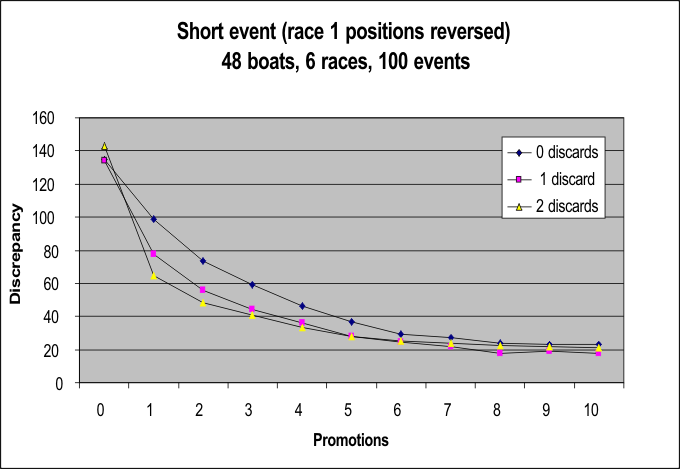
These two graphs show that, if an event has a discrepancy score of 6, then around 2 units of discrepancy (one third of the total) come from variation in race-by-race ability (usually set at 25% in the simulation), and around 4 units of discrepancy (two-thirds of the total) come from race incidents (usually set at 0.15). This might help in the choice of these parameters for a particular simulation. Short events? The following simulates a short event, probably one day, of 6 races (3 heats per race). The fleet ability spread is "hard J", and the weighting scheme is "egalitarian", so it is meant to characterise a Sunday event. And, in this run, the results of race 1 were reversed so that all the top boats started race 2 in heat C, and all the bottom boats started in heat A. It is pretty clear that the discrepancy score is minimised only if at least 8 boats are promoted per heat.
|
|
©2025 Lester Gilbert |